
(This is a video, you may need to wait some time before totally loading it.)
Most of the existing video face super-resolution (VFSR) methods are trained and evaluated on VoxCeleb1, which is designed specifically for speaker identification and the frames in this dataset are of low quality. As a consequence, the VFSR models trained on this dataset can not output visual-pleasing results. In this paper, we develop an automatic and scalable pipeline to collect a high-quality video face dataset (VFHQ), which contains over 16,000 high-fidelity clips of diverse interview scenarios. To verify the necessity of VFHQ, we further conduct experiments and demonstrate that VFSR models trained on our VFHQ dataset can generate results with sharper edges and finer textures than those trained on VoxCeleb1. In addition, we show that the temporal information plays a pivotal role in eliminating video consistency issues as well as further improving visual performance. Based on VFHQ, by analyzing the benchmarking study of several state-of-the-art algorithms under bicubic and blind settings.
The clips in VFHQ are high-quality.
(This is a video, you may need to wait some time before
totally
loading it.)
The scenarios in VFHQ are diverse.
(This is a video, you may need to wait some time before
totally
loading it.)
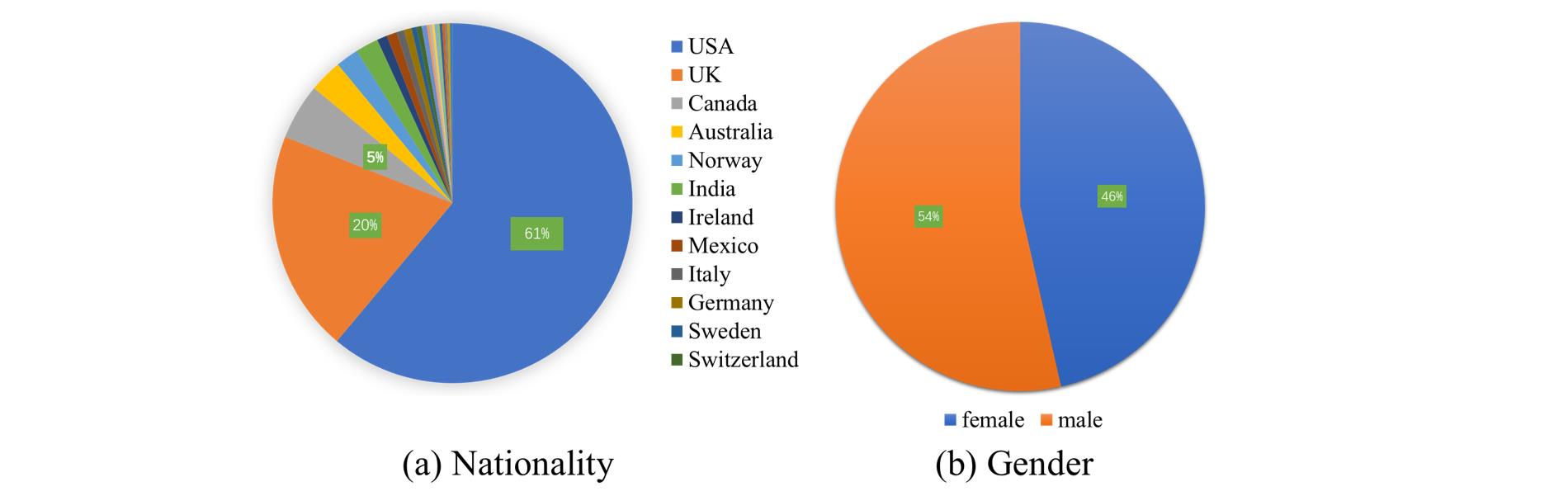
As shown in (a), VFHQ includes persons that come from more than 20 distinct countries. In (b), we notice that the proportion of men and women is roughly the same.
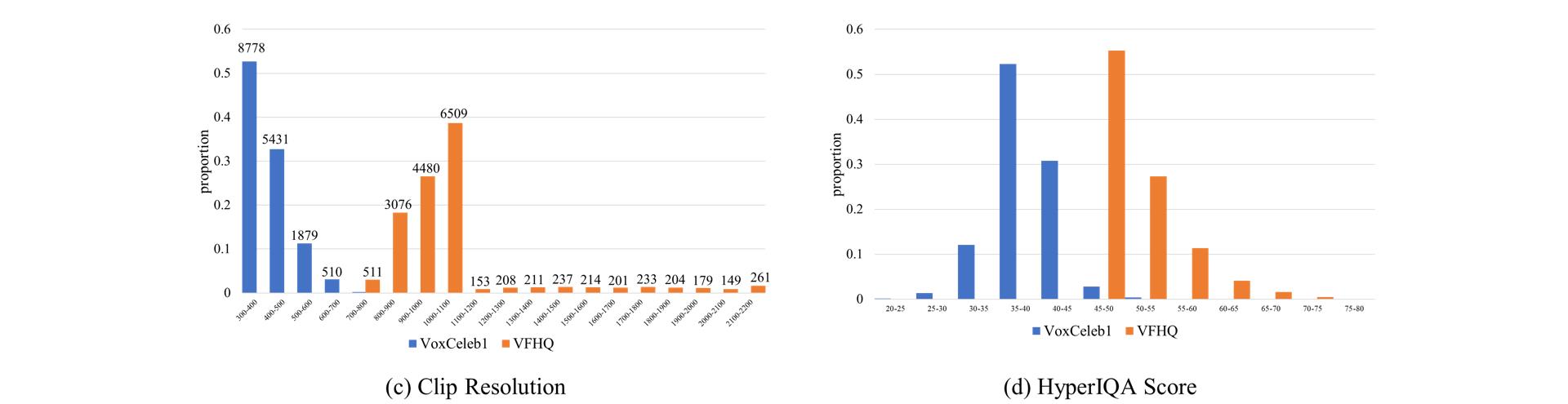
The figure (c) demonstrates that the distribution of clip resolution of our VFHQ is different from VoxCeleb1 and the resolution of VFHQ is much higher than VoxCeleb1. Above the bar is the number of clips. Note that we use the length of the shortest side as the clip resolution. The figure (d) shows that the quality of VFHQ is higher than VoxCeleb1 quantitatively.
We provide a processing script that extracts high-resolution faces from meta info. We also provide the processed VFHQ dataset and the resized 512x512 version. Note that the usage of VFHQ must comply with the agreement that mentioned in the next section.
| Name | Size | Clips | Links | Description |
|---|---|---|---|---|
| vfhq-dataset | 4.2 TB | Main folder | ||
| ├ meta_info | 170 MB | 15,381 | 百度网盘 | Metadata including video id, face landmarks, etc. |
| ├ VFHQ_zips | 2.8 TB | 15,204 | 百度网盘 | Zips of VFHQ (w/o resize operation). |
| ├ VFHQ-512 | 1.2 TB | 15,381 | 百度网盘 | Resized 512x512 version of VFHQ. |
| ├ VFHQ-Test | 2.37 GB | 100 | 百度网盘 | Test dataset adopted in the paper. |
| └ resize.py | 百度网盘 | Resize script. |
We release the trained models used in our benchmarking experiments.
For the bicubic setting (for scaling factor X4 and X8), we release the pre-trained
weights
of RRDB,
ESRGAN,
EDVR(frame=5),
EDVR+GAN(frame=5), BasicVSR(frame=7), BasicVSR-GAN(frame=7).
For the blind setting (for scaling factor X4),
we release the pre-trained weights of EDVR(frame=5), EDVR+GAN(frame=5), BasicVSR(frame=7),
BasicVSR-GAN(frame=7).
All of the models are trained based on the BasicSR framework, and the specific training
settings are also
referenced from BasicSR.
| Name | Links | Description |
|---|---|---|
| pretrained_models | Main folder | |
| ├ Cubic-Setting-X4 | 百度网盘 | Pre-trained weights of models for bicubic setting with scale X4. |
| ├ Cubic-Setting-X8 | 百度网盘 | Pre-trained weights of models for bicubic setting with scale X8. |
| └ Blind-Setting-X4 | 百度网盘 | Pre-trained weights of models for blind setting with scale X4. |
For blind setting, we provide the dataset pipeline in training phase. Besides, we also provide a yaml file which contains the detailed range of different degradation types.
If you find this helpful, please cite our work:
@InProceedings{xie2022vfhq,
author = {Liangbin Xie and Xintao Wang and Honglun Zhang and Chao Dong and Ying Shan},
title = {VFHQ: A High-Quality Dataset and Benchmark for Video Face Super-Resolution},
booktitle={The IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)},
year = {2022}
}